
内容简介
本文主要介绍深度学习图像分类的经典网络结构及发展历程。就细粒度图像分类中的注意力机制进行综述。最后给出汽车之家团队参加CVPR2022细粒度分类竞赛所使用的模型及相关算法。参赛经验及该模型在汽车之家车系识别业务中的应用。对于想了解图像分类任务。相关比赛技巧及业务应用的读者有一定借鉴意义。
1. 基于深度学习的图像分类神经网络
自AlexNet[1]横空出世。在ImageNet[2]竞赛中取得62.5%的top-1准确率。超越SIFT+FVs[3]类传统算法8.2%之后。深度神经网络就成为了图像分类领域的主要算法。先后出现了VGG[4]。ResNet[5]。Inception[6]。DenseNet[7]等。2019年。谷歌提出的EfficientNet[8]更是将网络结构设计由人工推向了自动搜索时代。2020年。谷歌提出的Vision Transformer(ViT)[9]。将自然语言处理领域的Transformer结构引入图像分类。将图像分类带入了Transformer时代。
VGG[4]由谷歌Deepmind和英国牛津大学的研究人员联合开发。使用多个级联的3x3小卷积核代替了7x7的大卷积核。在保证感受野的基础上大大降低了网络的参数量。VGG[4]的另外一个贡献是通过加深网络结构提升了分类精度。在ImageNet[2]数据集上使用19层网络。top-1分类准确率达到了74.5%。
2015年。当时还在微软从事研究的何凯明。孙剑等人提出了ResNet[5]。通过引入图1的残差结构。有效解决了深层神经网络训练过程中的梯度消失和梯度爆炸问题。同时解决了随着网络加深。分类精度越来越差的“退化”问题。首次在ImageNet[2]数据集上使用152层的超深网络获得了较好的分类精度。top-1准确率达到了78.57%。获得了2015年ImageNet[2]竞赛分类赛道的第一名。
图1 残差模块
在以何凯明为代表的一些研究人员通过加深网络深度提升分类效果的同时。谷歌的一些研究人员在网络宽度上也取得了较大进展。先后在2014~2016年提出了InceptionV1~V4网络结构。InceptionV1[5]网络的设计思路主要是使用稠密组件(dense components)近似网络中的稀疏结构。为此。谷歌的研究人员剔除了图2所示的Inception基本结构。这种结构使用了多个并行的卷积和最大池化。在近似稀疏结构的同时。还引入了多尺度特性。InceptionV2[6]在借鉴VGG[4]等论文。使用多个级联3x3卷积代替5x5卷积的基础上。还加入了Batch Normalization(BN)对数据进行归一化。top-1准确率达到了74.8%。InceptionV3[6]提出了一种可有效降低网络参数量的方法。即非对称分解(Asymmetric Factorization)。非对称分解就是将nxn卷积分解为1xn和nx1的级联形式。top-1准确率达到了78.8%。InceptionV4则将ResNet[5]中使用的残差结构融入Inception模块。极大加快了训练速度。。top-1准确率达到了80.10%。
图2 Inception 模块
在网络深度和宽度的研究取得长足进步之后。一些研究人员开始考虑通过网络特征的重用。提升网络的分类效果。比较典型的就是2017年CVPR的最佳论文DenseNet[9]。ResNet[5]证明了残差短连接能有效解决梯度消失和网络退化问题。如图3所示DenseNet借鉴了这一思想。将短连接使用在了所有层之间。对于一个L层的网络的第N层。前N-1层的特征在第N层实现了特征融合。同时。第N层的特征也提供给后边L-N层进行特征融合。特征重用避免了无效特征的重复提取。在提升网络的分类精度的同时。也有效降低了网络的参数量。DenseNet[9]在ImageNet[2]数据集上的top-1准确率达到了79.2%
至此。人工设计网络结构的相关工作开始进入了百花齐放的时代。与此同时。谷歌大脑(Google Brain)的研究人员于2018年提出了神经网络结构搜索(Neural Architecture Search)。此后。神经网络设计进入了自动化时代。由于NAS需要的计算资源较大。因此早期NAS都是在一个小数据集上。如CIFAR-10。搜索出一个基础卷积结构单元(Cell)。之后再通过复制这些基础卷积结构单元。“迁移”到如ImageNet[2]这样的大数据集上。如图4所示。网络搜索过程由一个RNN网络控制。基础卷积结构单元接收”hidden state”列表里前两个状态hi和hi-1或列表里的两个状态的输出(图4中的灰色方框)。之后从图5所示的操作中选择2个(图4中的黄色方框)。作用在选出的两个状态上。最后再使用加法(add)或叠加(concat)(图4中的绿色方框)的融合方法进行融合。不断迭代增加新的基础卷积结构单元。直到基础卷积结构单元的数量达到预设的N。使用这种网络搜索算法。搜出的NASNet[10]在ImageNet[2]数据集上的top-1准确率达到了82.7%。达到和超越了人工设计的网络结构。
NASNet[10]开启了神经网络搜索时代。实现了网络结构的设计的自动化。但其缺陷也比较明显。NASNet[10]的搜索空间仍然是人为设定的。是一种基于给定搜索空间的网络结构搜索算法。针对这一问题。FAIR何凯明团队2020年提出了用于设计搜索空间的方法。RegNet[12]论文中将网络结构搜索空间也作为网络结构设计的一部分。如图6所示。通过不断优化网络搜索空间。同时获得了最佳的搜索空间和该搜索空间中的最佳网络结构。
2020年。谷歌提出ViT(Vision Transformer)[13]。将NLP(Natural Language Processing)领域使用的Transformer引入视觉领域。将图像分为分辨率相同的若干子块。每一个子块作为NLP领域的一个字符(token)进行处理。Transformer自注意力机制的引入。极大提高了网络的分类效果。在ImageNet[2]数据集上的top-1准确率达到了88.55%。
图3 DenseNet
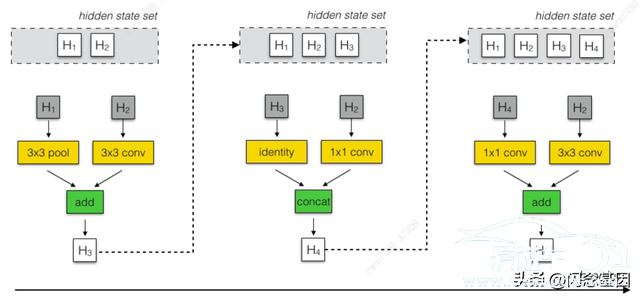
图4 RNN控制器
图5 NASNet基础卷积结构单元
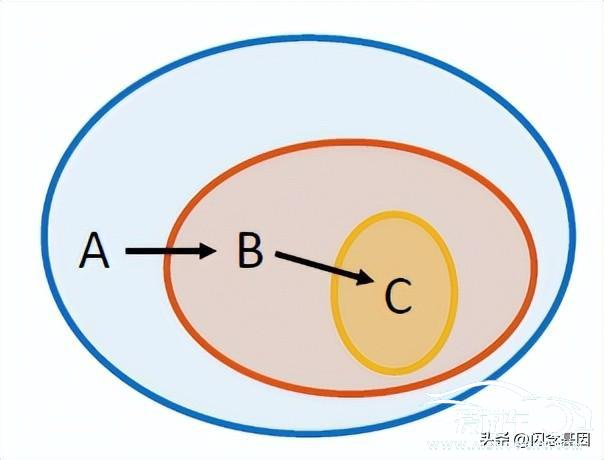
图6 搜索空间
2. 基于深度学习的图像细粒度分类
在过去的十年。深度学习推动图像分类取得了长足进步。但常见的图像分类数据集。如ImageNet[2]。中的类别的粒度仍然较粗。比如。狗这个类别下。还可以细分为拉布拉多。金毛寻回犬。边境牧羊犬等细分类别。粗粒度的分类已经越来越无法满足实际生产生活的需要。学术界及工业界迫切希望深度学习能在细粒度分类任务中发挥重要作用。与粗粒度分类不同。细粒度分类更加关注物体细节之间的差异。需要模型更加注意一些细节。因此。学术界提出了“注意力”机制。
近年来。注意力机制被广泛引入细粒度分类领域。出现了如SE[14]。GE[15]。CBAM[16]。SK[17]等注意力模块。这些模块被融入各种网络结构中。有效地提升了分类效果。
SE模块提出相对较早。2017年由Momenta提出。由SE模块构建的SENet也成为了2017年末代ImageNet[2]分类竞赛的冠军网络。卷积神经网络(CNN)同时融合空间和通道信息。SE模块则更加关注通道信息的融合。如图7所示。对Feature Map U首先进行Squeeze操作。得到一个通道描述子。该描述子主要用来描述各通道的响应分布。紧接着对该描述子进行excitation操作。得到各通道权值向量。并使用该权值向量对Feature Map的各通道进行加权。加强权值较大的通道。抑制权值较低的通道。通过这种方式实现了通道注意力机制。
使用SE[14]模块实现通道注意力机制之后。Momenta又在2018年提出了空间注意力模块GE[15]。如图8所示。GE[15]使用自定义的Gather和Excite模块实现了空间感受野区域的注意力机制。
2018年。还出现了另一个同时融合通道。空间注意力的注意力模块。即CBAM[16]。如图9所示。对于任意一个Feature Map。CBAM模块先后提取通道和空间注意力信息。并分别跟相应的Feature Map进行加权。同时实现了通道和空间注意力。
通道。空间注意力被相继引入之后。SK[17]模块又将多尺度特征这一计算机视觉领域常用的方法引入了注意力机制。如图10所示。SK模块首先使用两个不同大小的卷积核处理Feature Map。再将结果相加。再经过一系列操作。得到了每一路的权值a和b。使用a和b对每一路Feature Map加权后。得到最终的Feature Map。
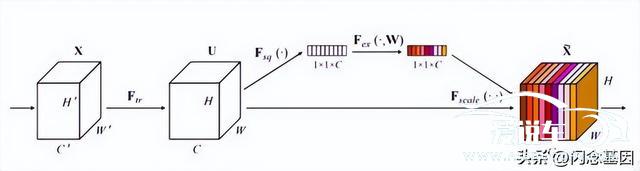
图7 SE(Squeeze & Excitation)模块
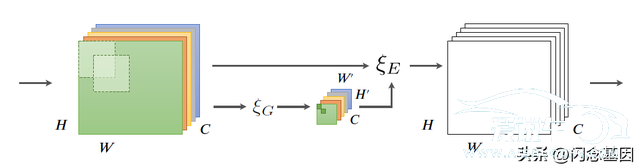
图8 GE(Gather & Excite)模块
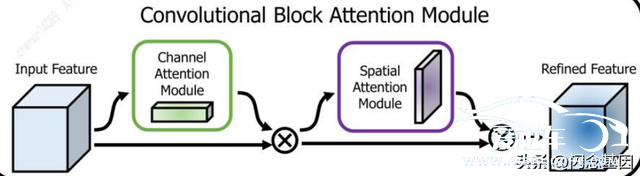
图9 CBAM模块
图10 SK模块
3. 基于深度学习的图像细粒度分类算法
在CVPR比赛中的应用
6月19日。CVPR 2022在美国举行。CVPR作为全球计算机视觉三大顶级会议之一。被誉为计算机视觉领域的“奥斯卡”。汽车之家团队在作为大会研讨会内容之一的。在Kaggle上举办的CVPR 2022 Sorghum-100 Cultivar Identification-FGVC 9(高粱品种鉴定细粒度图像分类)挑战赛中取得了第二名的成绩。实现了公司历史上的突破。
细粒度图像分类一直是计算机视觉领域的研究热点。主要难点在于细粒度标注图像的类间距离小。类内距离大导致部分图像的类别靠人眼都很难分辨。比如。此次FGVC9的比赛中。高粱品种鉴定和植物标本识别竞赛的数据需要很强的专业知识才能判定图像所属类别。如图11所示。两个圈内的同样颜色的样本之间的距离称为类内距。不同颜色的样本之间的距离称为类间距。
图11 类内距和类间距
本次比赛中。主要使用了RegNetY-16.0GF作为主干网。大分辨率图像对精度的提升起到了很大作用。当将图像分辨率由512增大到960之后。精度在私榜上由84.1提升到了91.9。因此。我们相信。大分辨率图像对于细粒度分类效果提升有较大帮助。
如前文所述。注意力机制的引入能极大提升细粒度图像分类模型的精度。除了作为主干网的RegNetY-16.0GF中的SE[14]模块之外。本次比赛中还提出了一种新型的注意力区域裁剪策略。注意力区域裁剪是细粒度图像分类领域常用的方法。如图12所示。SCDA[18]使用最大联通域的方法。将注意力区域裁剪出来。避免了不相关区域对模型训练的影响。使模型更加关注注意力区域。最大连通域法对于注意力区域比较明显的情况。如图12所示的鸟。处理效果较好。对于Sorghum-100数据集则很难适用。如图13所示。Sorghum-100数据集的注意力区域比较分散。使用最大连通域的方法裁剪注意力区域的话。在得到较好的注意力区域的同时。会丢失一部分注意力区域。降低模型的分类精度。因此。我们提出了一种注意力区域随机裁剪法。该方法的流程图如图14所示。输入图像经过一个Epoch训练之后。可以得到一个模型。使用该模型预测所有训练图像。对训练原图进行裁剪。将裁剪后的结果作为下一个Epoch的训练数据。如此循环。直到训练结束。随机裁剪流程如图15所示。使用第n个Epoch训练出的模型对训练图像进行预测。得到全连接层之前输出的注意力图像。如图13所示。使用阈值T对注意力图像进行二值化。得到黑白图G。假设随机crop的图像的宽高分别为w和h。可以对图G进行N此裁剪。包含白色区域最多的区域(x。y。w。h)即为第n+1个Epoch该图用于训练的区域。
使用这种注意力区域随机裁剪法。一方面保证了模型更关注注意力区域。另一方面又避免了由于注意力区域较分散造成的信息丢失。
图12 SCDA
图13 注意力区域随机裁剪
图14 注意力区域随机裁剪
图15 随机裁剪流程图
数据增强方面。除了常见的左右翻转。随机裁剪之外。还使用了谷歌在CVPR2019论文中提出的AutoAugment[19]。该方法通过参数搜索。获得了在常见数据集。如CIFAR。ImageNet等。上的最佳增强策略。
Pseudo Label作为一种常用的自监督学习方法。也被广泛用于图像分类领域。每次训练结束之后。都使用训练出的最佳模型。对测试集进行预测。将预测结果作为标注信息。加入训练集。不断循环。直到测试集准确率没有明显提升。本次比赛中。加入Pseudo Label之后。私榜上精度由91.9提升到了95.1。
Test Time Augmentation(TTA)作为一种常见的测试技巧。也被应用到了本次比赛中。数据增强除了在训练阶段可以用来避免过拟合。提升模型泛化性之外。在测试阶段也可以有效提升模型精度。
Dropout作为一种有效防止过拟合的方法。在比赛的最后阶段。dropout的加入使模型精度在私榜上由95.1提升到95.3。
Ensemble也是一种竞赛常见技巧。将不同模型预测的embedding进行加权。再使用加权后的embedding进行预测。也可以有效提升模型精度。本次比赛的最后阶段。Ensemble的加入使模型精度在私榜上由95.3提升到95.9。
4. 基于深度学习的图像细粒度分类算法
在汽车之家车系识别业务中的应用
汽车之家作为汽车互联网垂直领域的领军企业。一直深耕如车系识别等汽车领域的人工智能算法。车系识别目前支持识别4000多个车系。涵盖奔驰。宝马。奥迪等绝大部分常见车系。应用于主APP的拍照识车。二手车/论坛信息校验等多个内部应用。
本次比赛结束之后。车系识别模型也使用了比赛中使用的RegNetY-16.0GF。准确率提升了3.25%。如图17所示。模型的注意力区域主要集中在车头位置。因此对于同一车系内部。车头外观相差较大的车系。识别准确率较差;同样。对于不同车系。车头外观较相似的车系。也容易混淆。即图11中提到的。细粒度分类问题中常见的。类间距离小。类内距离大问题。
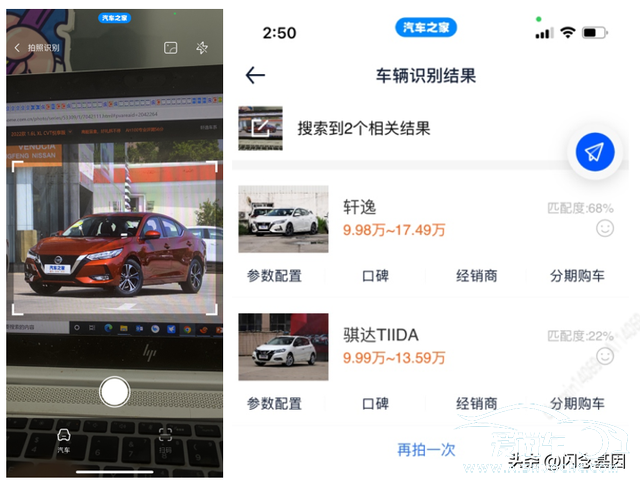
图16 汽车之家主app拍照识车
图17 车系识别模型注意力图
5. 总结及展望
近年来。深度学习的发展极大推动了细粒度分类在交通。医疗。工业。农业。电商等领域的落地。各种反应工业界需求的相关比赛也吸引了大量从业者参加。如专注自然物种分类的iNat Challenge 2021[20]。关于渔业资源保护的Fisheries Monitoring[21]。阿里巴巴主办的AliProducts Challenge等。与一般图像分类问题相似。细粒度分类的发展也面临着诸多挑战:
数据标注:细粒度图像的标注往往需要相关专业知识(如医学等)。这给标注带来了极大困难。因此。自监督学习是未来的一大趋势。FAIR的何凯明团队最近提出的自监督学习框架MAE[23]在Imagenet[2]分类任务上取得了SOTA(State of Art)的结果。相信在不久的将来。自监督学习也会在细粒度分类任务上取的骄人的成绩。识别鲁棒性:众所周知。图像分类问题受图像质量影响较大。暗光。过曝。模糊等图像质量问题都会影响到图像分类的精度。这一影响对细粒度分类尤其严重。如何提高细粒度分类模型的鲁棒性也是这一领域从业者面临的较大挑战。训练集不包含的类别:在一个图像分类数据集上训练的模型往往难以分辨该数据集之外的图像。有时会把这部分图像误识为训练集中的某一类别。也就是学术界常常提到的OOD(Out of Distribution)问题。这类问题往往需要前置一个检测或分割模型。将模型不能识别的类别的图像筛选出来。如果在训练集中增加“其他”这一类别。由于其他类包含太广。识别效果往往不好。因此。这一问题的解决也将是细粒度分类领域的一大挑战。小样本识别(长尾):细粒度分类的很多类别数据收集较困难。因此会出现训练/测试样本不均衡问题。也就是业界常常提到的“长尾”问题。这就导致模型对数据量较大的类别识别效果较好。对数据量较小的类别识别效果较差。参考文献
[1]. Krizhevsky。 A.。 Sutskever。 I.。 and Hinton。 G. E. ImageNet classification with deep convolutional neural networks. In NIPS。 pp. 1106–1114。 2012
[2]. Deng。 J.。 Dong。 W.。 Socher。 R.。 Li。 L.-J.。 Li。 K.。 and Fei-Fei。 L. Imagenet: A large-scale hierarchical image database. In Proc. CVPR。 2009
[3]. J. Sánchez and F. Perronnin. High-dimensional signature compression for large-scale image classification. In Computer Vision and Pattern Recognition (CVPR)。 2011 IEEE Conference on。 pages 1665–1672. IEEE。 2011
[4]. K. Simonyan。 A. Zisserman。 Very Deep Convolutional Networks for Large-Scale Image Recognition. In International Conference on Learning Representations。 2015
[5]. K. He。 X. Zhang。 S. Ren and J. Sun。 "Deep Residual Learning for Image Recognition。" 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)。 2016。 pp. 770-778。 doi: 10.1109/CVPR.2016.90.
[6]. C. Szegedy et al.。 "Going deeper with convolutions。" 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)。 2015。 pp. 1-9。 doi: 10.1109/CVPR.2015.7298594.
[7]. C. Szegedy。 V. Vanhoucke。 S. Ioffe。 J. Shlens and Z. Wojna。 "Rethinking the Inception Architecture for Computer Vision。" 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)。 2016。 pp. 2818-2826。 doi: 10.1109/CVPR.2016.308.
[8]. Szegedy。 C.。 Ioffe。 S.。 Vanhoucke。 V.。 et al. Inception-v4。 Inception-Resnet and the Impact of Residual Connections on Learning. Thirty-First AAAI Conference on Artificial Intelligence。 San Francisco。 4-9 February 2017。 4278-4284.2017
[9]. G. Huang。 Z. Liu。 L. Van Der Maaten and K. Q. Weinberger。 "Densely Connected Convolutional Networks。" 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)。 2017。 pp. 2261-2269。 doi: 10.1109/CVPR.2017.243.
[10]. B. Zoph。 V. Vasudevan。 J. Shlens and Q. V. Le。 "Learning Transferable Architectures for Scalable Image Recognition。" 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition。 2018。 pp. 8697-8710。 doi: 10.1109/CVPR.2018.00907.
[11]. R. Doon。 T. Kumar Rawat and S. Gautam。 "Cifar-10 Classification using Deep Convolutional Neural Network。" 2018 IEEE Punecon。 2018。 pp. 1-5。 doi: 10.1109/PUNECON.2018.8745428.
[12]. N. Schneider。 F. Piewak。 C. Stiller and U. Franke。 "RegNet: Multimodal sensor registration using deep neural networks。" 2017 IEEE Intelligent Vehicles Symposium (IV)。 2017。 pp. 1803-1810。 doi: 10.1109/IVS.2017.7995968.
[13]. Alexey Dosovitskiy。 Lucas Beyer。 Alexander Kolesnikov。 Dirk Weissenborn。 Xiaohua Zhai。 Thomas Unterthiner。 Mostafa Dehghani。 Matthias Minderer。 Georg Heigold。 Sylvain Gelly。 Jakob Uszkoreit。 Neil Houlsby。 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021
[14]. J. Hu。 L. Shen and G. Sun。 "Squeeze-and-Excitation Networks。" 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition。 2018。 pp. 7132-7141。 doi: 10.1109/CVPR.2018.00745.
[15]. Jie Hu and Li Shen and Samuel Albanie and Gang Sun and Andrea Vedaldi。 Gather-Excite: Exploiting
Feature Context in Convolutional Neural Networks。NIPS 2018
[16]. Woo。 S.。 Park。 J.。 Lee。 JY.。 Kweon。 I.S. (2018). CBAM: Convolutional Block Attention Module. In: Ferrari。 V.。 Hebert。 M.。 Sminchisescu。 C.。 Weiss。 Y. (eds) Computer Vision – ECCV 2018.
[17]. X. Li。 W. Wang。 X. Hu and J. Yang。 "Selective Kernel Networks。" 2019 IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR)。 2019。 pp. 510-519。 doi: 10.1109/CVPR.2019.00060.
[18]. X. Wei。 J. Luo。 J. Wu and Z. Zhou。 "Selective Convolutional Descriptor Aggregation for Fine-Grained
Image Retrieval。" in IEEE Transactions on Image Processing。 vol. 26。 no. 6。 pp. 2868-2881。 June 2017。
doi: 10.1109/TIP.2017.2688133.
[19]. E. D. Cubuk。 B. Zoph。 D. Mané。 V. Vasudevan and Q. V. Le。 "AutoAugment: Learning Augmentation
Strategies From Data。" 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition
(CVPR)。 2019。 pp. 113-123。 doi: 10.1109/CVPR.2019.00020.
[20]. iNat Challenge 2021 https://www.kaggle.com/c/inaturalist-2021
[21]. Fisheries Monitoring https://www.kaggle.com/competitions/the-nature-conservancy-fisheries-monitoring/
[22]. https://tianchi.aliyun.com/competition/entrance/531884/introduction
[23]. Kaiming He and Xinlei Chen and Saining Xie and Yanghao Li and Piotr Dollar and Ross Girshick。
Masked Autoencoders Are Scalable Vision Learners。 IEEE/CVF Conference on Computer Vision and
Pattern Recognition。 2022
作者简介
本文作者陈心。韩沛奇。张磊。来自智能数据中心-图像组。主要从事图像相关算法研发。落地。包括车系识别。车辆检测。人脸检测。图像去重。人脸识别。图文多模态等。
来源:微信公众号:之家技术
出处:https://mp.weixin.qq.com/s?__biz=MzUyMzg4ODk2NQ==&mid=2247490929&idx=1&sn=630c43bff5f57ac860c36cf9dc68acc6







